1 部署 Docker 服务
| curl https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker.repo | |
| yum list docker-ce –showduplicates | sort -r # 显示所有版本 | |
| yum install -y docker-ce-20.10.5 # 指定 docker 版本 | |
| systemctl start docker # 启动 docker 服务 | |
| systemctl status docker # 查看 docker 服务状态 | |
| systemctl enable docker # 设置 docker 开机自启动 |
2 部署 Prometheus 服务
创建 mon 用户,创建目录:
| groupadd -g 2000 mon | |
| useradd -u 2000 -g mon mon | |
| mkdir -p /home/mon/prometheus/{etc,data,rules} |
创建配置文件:
| vim /home/mon/prometheus/etc/prometheus.yml |
| # my global config | |
| global: | |
| scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. | |
| evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. | |
| # scrape_timeout is set to the global default (10s). | |
| # Alertmanager configuration | |
| alerting: | |
| alertmanagers: | |
| – static_configs: | |
| – targets: | |
| # – alertmanager:9093 | |
| # Load rules once and periodically evaluate them according to the global ‘evaluation_interval’. | |
| rule_files: | |
| # – “first_rules.yml” | |
| # – “second_rules.yml” | |
| # A scrape configuration containing exactly one endpoint to scrape: | |
| # Here it’s Prometheus itself. | |
| scrape_configs: | |
| # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. | |
| – job_name: ‘prometheus’ | |
| # metrics_path defaults to ‘/metrics’ | |
| # scheme defaults to ‘http’. | |
| static_configs: | |
| – targets: [‘localhost:9090’] |
启动容器服务:
| docker pull prom/prometheus | |
| cd /home/mon/ | |
| chown mon. -R prometheus | |
| docker run -d –user root -p 9090:9090 –name prometheus \ | |
| -v /home/mon/prometheus/etc/prometheus.yml:/etc/prometheus/prometheus.yml \ | |
| -v /home/mon/prometheus/rules:/etc/prometheus/rules \ | |
| -v /home/mon/prometheus/data:/data/prometheus \ | |
| prom/prometheus \ | |
| –config.file=“/etc/prometheus/prometheus.yml” \ | |
| –storage.tsdb.path=“/data/prometheus” \ | |
| –web.listen-address=“0.0.0.0:9090” |
3 部署 Grafana 服务
创建数据目录:
| mkdir -p /home/mon/grafana/plugins |
安装插件:下载Grafana插件
| tar zxf /tmp/grafana-plugins.tar.gz -C /home/mon/grafana/plugins/ | |
| chown -R mon. /home/mon/grafana | |
| chmod 777 -R /home/mon/grafana |
启动容器服务:
| docker pull grafana/grafana:latest | |
| docker run -d -p 3000:3000 -v /home/mon/grafana:/var/lib/grafana –name=grafana grafana/grafana:latest |
4 配置 Grafana 对接 Prometheus
访问 http://ip:3000,初始账号密码为 admin/admin,会要求更改密码。
按照如下截图顺序配置 Prometheus Dashboard:

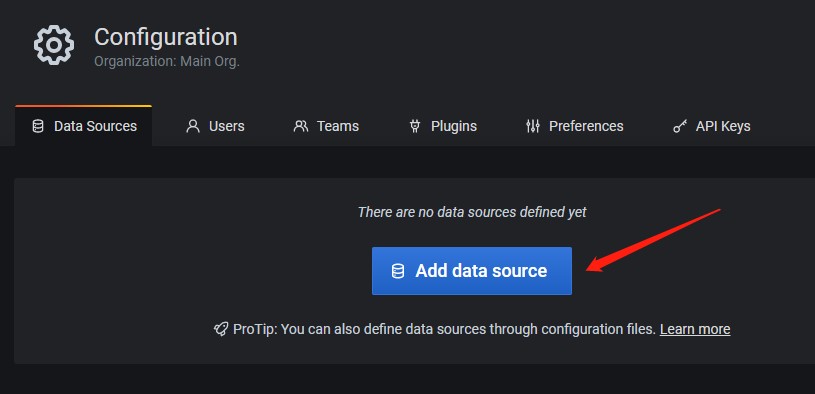
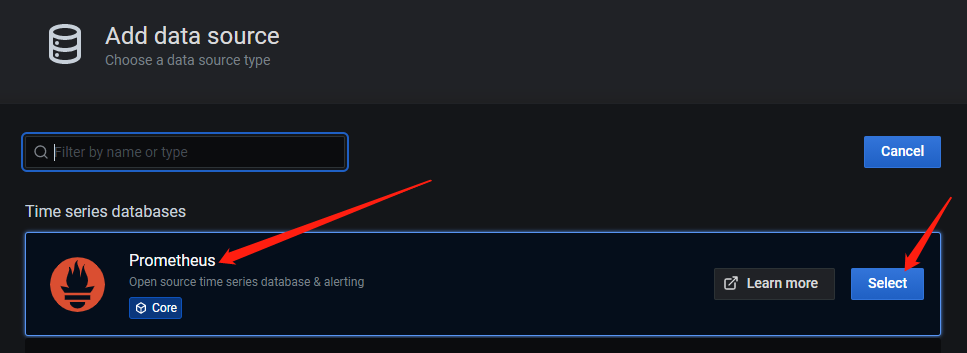
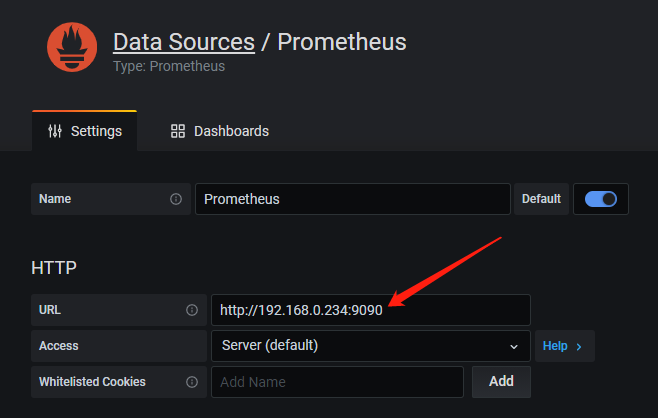
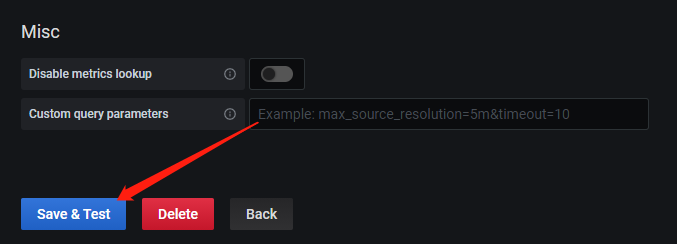
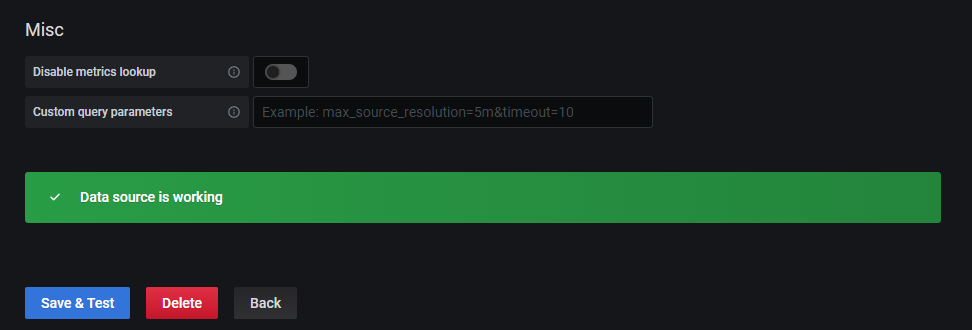
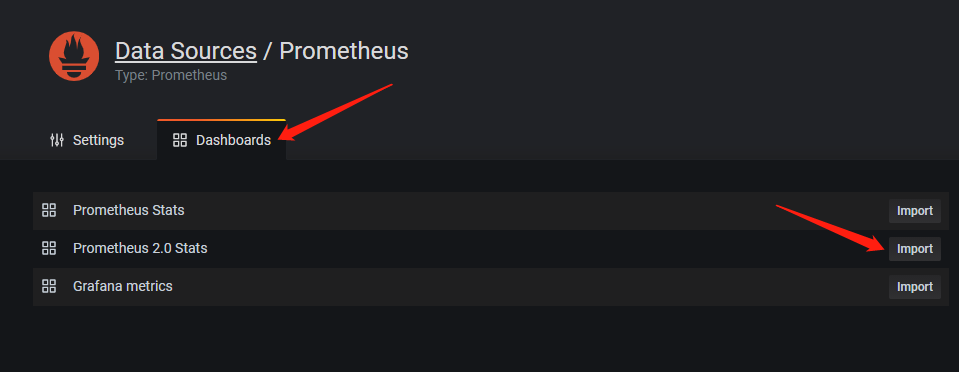
5 部署 Node_Exporter 服务
我以监控一台阿里云ECS为例。
安装配置Node_Exporter:
| curl https://github.com/prometheus/node_exporter/releases/download/v1.1.1/node_exporter-1.1.1.linux-amd64.tar.gz > /opt/node_exporter-1.1.1.linux-amd64.tar.gz | |
| cd /opt | |
| tar zxf node_exporter-1.1.1.linux-amd64.tar.gz | |
| mv node_exporter-1.1.1.linux-amd64 node_exporter |
配置服务启动脚本:
| vim /usr/lib/systemd/system/node_exporter.service | |
| [Unit] | |
| Description=node_exporter service | |
| [Service] | |
| User=root | |
| ExecStart=/opt/node_exporter/node_exporter | |
| TimeoutStopSec=10 | |
| Restart=on-failure | |
| RestartSec=5 | |
| [Install] | |
| WantedBy=multi-user.target |
| systemctl daemon-reload | |
| systemctl start node_exporter | |
| systemctl status node_exporter | |
| systemctl enable node_exporter |
在这台ECS服务器的Nginx下配置反向代理:
| vim /opt/nginx/conf/conf.d/blog.conf | |
| # prometheus monitor node exporter | |
| location /node/service { | |
| proxy_pass http://127.0.0.1:9100/metrics; | |
| proxy_set_header Host $http_host; | |
| proxy_set_header X-Real-IP $remote_addr; | |
| proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; | |
| proxy_set_header X-Forwarded-Proto $scheme; | |
| } |
| /opt/nginx/sbin/nginx -s reload |
在Prometheus服务器端修改 配置文件:
| vim /home/mon/prometheus/etc/prometheus.yml | |
| – job_name: ‘node-service’ | |
| static_configs: | |
| – targets: [‘blog.iuskye.com’] | |
| labels: | |
| instance: node-service | |
| scheme: https | |
| metrics_path: /node/service |
重启 Prometheus 容器:
| docker restart prometheus |
验证是否获取到数据,在浏览器输入:https://blog.iuskye.com/node/service:
| # HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. | |
| # TYPE go_gc_duration_seconds summary | |
| go_gc_duration_seconds{quantile=“0”} 0 | |
| go_gc_duration_seconds{quantile=“0.25”} 0 | |
| go_gc_duration_seconds{quantile=“0.5”} 0 | |
| go_gc_duration_seconds{quantile=“0.75”} 0 | |
| go_gc_duration_seconds{quantile=“1”} 0 | |
| go_gc_duration_seconds_sum 0 | |
| go_gc_duration_seconds_count 0 | |
| # HELP go_goroutines Number of goroutines that currently exist. | |
| # TYPE go_goroutines gauge | |
| go_goroutines 7 | |
| # HELP go_info Information about the Go environment. | |
| # TYPE go_info gauge | |
| go_info{version=“go1.15.8”} 1 | |
| # HELP go_memstats_alloc_bytes Number of bytes allocated and still in use. | |
| # TYPE go_memstats_alloc_bytes gauge | |
| ······ |
创建Dashboard:

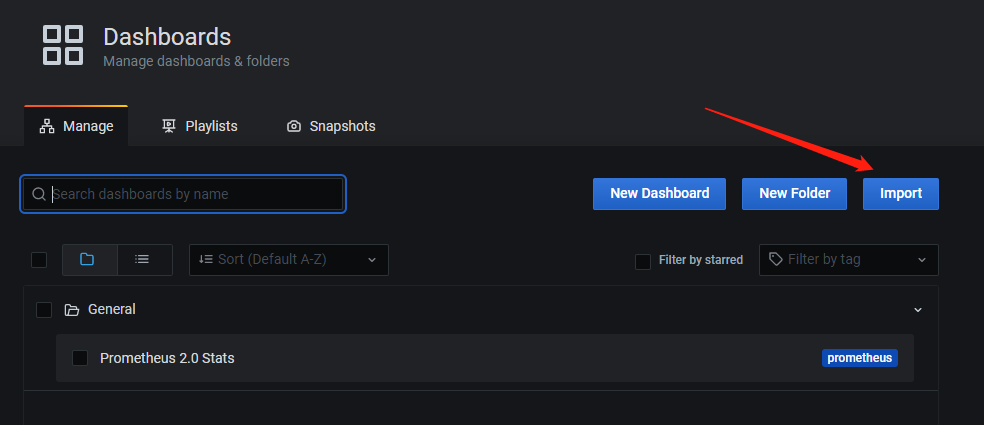
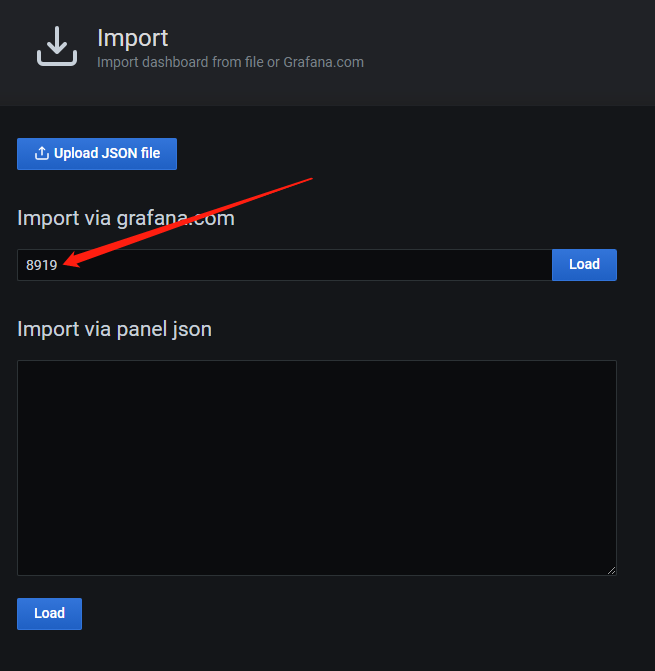
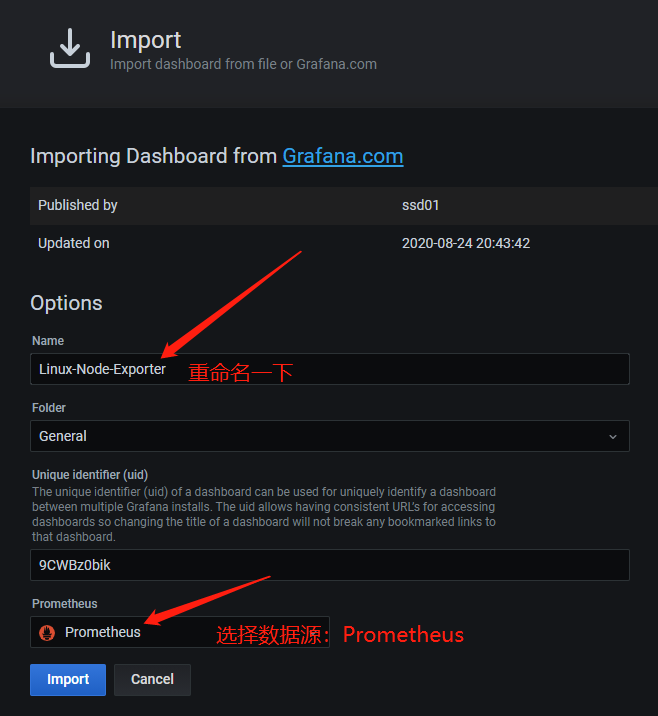
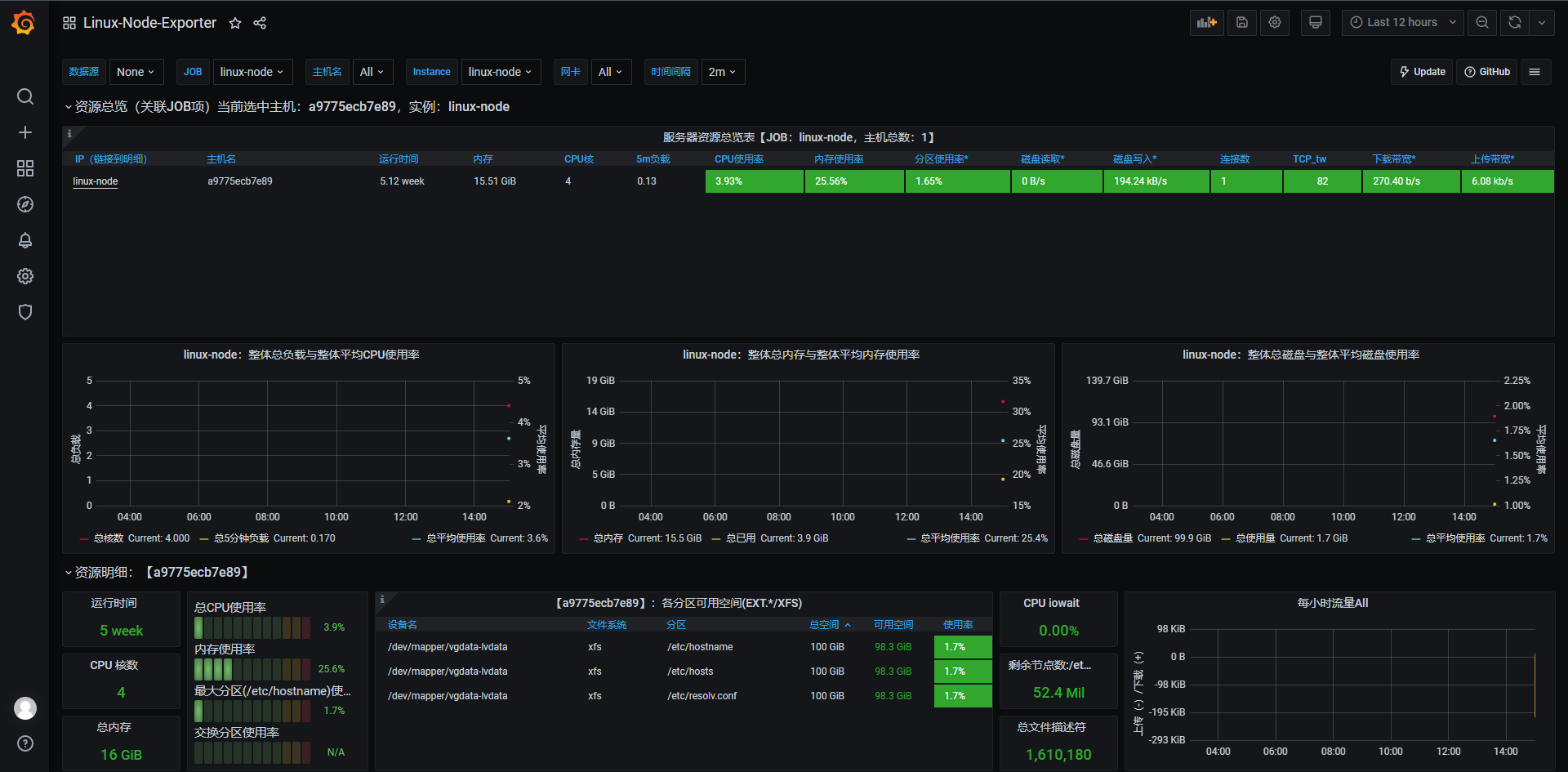
6 部署 Alertmanager 服务
创建目录:
| mkdir -p /home/mon/alertmanager/{etc,data} | |
| chmod 777 -R /home/mon/alertmanager |
创建配置文件:
| vim /home/mon/alertmanager/etc/alertmanager.yml | |
| global: | |
| resolve_timeout: 5m | |
| smtp_from: ‘[email protected]’ | |
| smtp_smarthost: ‘smtp.qq.com:465’ | |
| smtp_auth_username: ‘[email protected]’ | |
| # 注意这里需要配置QQ邮箱的授权码,不是登录密码,授权码在账户配置中查看 | |
| smtp_auth_password: ‘abcdefghijklmmop’ | |
| smtp_require_tls: false | |
| route: | |
| group_by: [‘alert_node’] | |
| group_wait: 5s | |
| group_interval: 5s | |
| repeat_interval: 5m | |
| receiver: ’email’ | |
| receivers: | |
| – name: ’email’ | |
| email_configs: | |
| # 请注意这里的收件箱请改为你自己的邮箱地址 | |
| – to: ‘[email protected]’ | |
| send_resolved: true | |
| inhibit_rules: | |
| – source_match: | |
| severity: ‘critical’ | |
| target_match: | |
| severity: ‘warning’ | |
| equal: [‘alert_node’, ‘dev’, ‘instance’] |
拉取镜像并启动容器:
| docker pull prom/alertmanager:latest | |
| chown -R mon. alertmanager/ | |
| docker run -d –user root -p 9093:9093 –name alertmanager \ | |
| -v /home/mon/alertmanager/etc/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ | |
| -v /home/mon/alertmanager/data:/alertmanager/data | |
| prom/alertmanager:latest \ | |
| –config.file=“/etc/alertmanager/alertmanager.yml” \ | |
| –web.listen-address=“0.0.0.0:9093” |
查看alertmanager容器IP地址,用于配置prometheus对接接口:
| docker exec -it alertmanager /bin/sh -c “ip a” | |
| 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 | |
| link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 | |
| inet 127.0.0.1/8 scope host lo | |
| valid_lft forever preferred_lft forever | |
| 10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue | |
| link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff | |
| inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0 | |
| valid_lft forever preferred_lft forever |
修改prometheus配置文件对接alertmanager:
| vim /home/mon/prometheus/etc/prometheus.yml | |
| alerting: | |
| alertmanagers: | |
| – static_configs: | |
| – targets: | |
| – 172.17.0.4:9093 | |
| rule_files: | |
| – “/etc/prometheus/rules/*rules.yml” |
配置告警规则:
| vim /home/mon/prometheus/rules/alert-node-rules.yml |
| groups: | |
| – name: alert-node | |
| rules: | |
| – alert: NodeDown | |
| # 注意:这里的job_name一定要跟prometheus配置文件中配置的相匹配 | |
| expr: up{job=“node-service”} == 0 | |
| for: 1m | |
| labels: | |
| severity: critical | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} is down” | |
| description: “Instance: {{ $labels.instance }} 已经宕机 1分钟” | |
| value: “{{ $value }}” | |
| – alert: NodeCpuHigh | |
| expr: (1 – avg by (instance) (irate(node_cpu_seconds_total{job=“node-service”,mode=“idle”}[5m]))) * 100 > 80 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} cpu使用率过高” | |
| description: “CPU 使用率超过 80%” | |
| value: “{{ $value }}” | |
| – alert: NodeCpuIowaitHigh | |
| expr: avg by (instance) (irate(node_cpu_seconds_total{job=“node-service”,mode=“iowait”}[5m])) * 100 > 50 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} cpu iowait 使用率过高” | |
| description: “CPU iowait 使用率超过 50%” | |
| value: “{{ $value }}” | |
| – alert: NodeLoad5High | |
| expr: node_load5 > (count by (instance) (node_cpu_seconds_total{job=“node-service”,mode=‘system’})) * 1.2 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} load(5m) 过高” | |
| description: “Load(5m) 过高,超出cpu核数 1.2倍” | |
| value: “{{ $value }}” | |
| – alert: NodeMemoryHigh | |
| expr: (1 – node_memory_MemAvailable_bytes{job=“node-service”} / node_memory_MemTotal_bytes{job=“node-service”}) * 100 > 60 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} memory 使用率过高” | |
| description: “Memory 使用率超过 90%” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskRootHigh | |
| expr: (1 – node_filesystem_avail_bytes{job=“node-service”,fstype=~“ext.*|xfs”,mountpoint =“/”} / node_filesystem_size_bytes{job=“node-service”,fstype=~“ext.*|xfs”,mountpoint =“/”}) * 100 > 90 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk(/ 分区) 使用率过高” | |
| description: “Disk(/ 分区) 使用率超过 90%” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskBootHigh | |
| expr: (1 – node_filesystem_avail_bytes{job=“node-service”,fstype=~“ext.*|xfs”,mountpoint =“/boot”} / node_filesystem_size_bytes{job=“node-service”,fstype=~“ext.*|xfs”,mountpoint =“/boot”}) * 100 > 80 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk(/boot 分区) 使用率过高” | |
| description: “Disk(/boot 分区) 使用率超过 80%” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskReadHigh | |
| expr: irate(node_disk_read_bytes_total{job=“node-service”}[5m]) > 20 * (1024 ^ 2) | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk 读取字节数 速率过高” | |
| description: “Disk 读取字节数 速率超过 20 MB/s” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskWriteHigh | |
| expr: irate(node_disk_written_bytes_total{job=“node-service”}[5m]) > 20 * (1024 ^ 2) | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk 写入字节数 速率过高” | |
| description: “Disk 写入字节数 速率超过 20 MB/s” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskReadRateCountHigh | |
| expr: irate(node_disk_reads_completed_total{job=“node-service”}[5m]) > 3000 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk iops 每秒读取速率过高” | |
| description: “Disk iops 每秒读取速率超过 3000 iops” | |
| value: “{{ $value }}” | |
| – alert: NodeDiskWriteRateCountHigh | |
| expr: irate(node_disk_writes_completed_total{job=“node-service”}[5m]) > 3000 | |
| for: 5m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk iops 每秒写入速率过高” | |
| description: “Disk iops 每秒写入速率超过 3000 iops” | |
| value: “{{ $value }}” | |
| – alert: NodeInodeRootUsedPercentHigh | |
| expr: (1 – node_filesystem_files_free{job=“node-service”,fstype=~“ext4|xfs”,mountpoint=“/”} / node_filesystem_files{job=“node-service”,fstype=~“ext4|xfs”,mountpoint=“/”}) * 100 > 80 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk(/ 分区) inode 使用率过高” | |
| description: “Disk (/ 分区) inode 使用率超过 80%” | |
| value: “{{ $value }}” | |
| – alert: NodeInodeBootUsedPercentHigh | |
| expr: (1 – node_filesystem_files_free{job=“node-service”,fstype=~“ext4|xfs”,mountpoint=“/boot”} / node_filesystem_files{job=“node-service”,fstype=~“ext4|xfs”,mountpoint=“/boot”}) * 100 > 80 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} disk(/boot 分区) inode 使用率过高” | |
| description: “Disk (/boot 分区) inode 使用率超过 80%” | |
| value: “{{ $value }}” | |
| – alert: NodeFilefdAllocatedPercentHigh | |
| expr: node_filefd_allocated{job=“node-service”} / node_filefd_maximum{job=“node-service”} * 100 > 80 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} filefd 打开百分比过高” | |
| description: “Filefd 打开百分比 超过 80%” | |
| value: “{{ $value }}” | |
| – alert: NodeNetworkNetinBitRateHigh | |
| expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~“eth0|eth1|ens33|ens37”}[1m]) * 8) > 20 * (1024 ^ 2) * 8 | |
| for: 3m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} network 接收比特数 速率过高” | |
| description: “Network 接收比特数 速率超过 20MB/s” | |
| value: “{{ $value }}” | |
| – alert: NodeNetworkNetoutBitRateHigh | |
| expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~“eth0|eth1|ens33|ens37”}[1m]) * 8) > 20 * (1024 ^ 2) * 8 | |
| for: 3m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} network 发送比特数 速率过高” | |
| description: “Network 发送比特数 速率超过 20MB/s” | |
| value: “{{ $value }}” | |
| – alert: NodeNetworkNetinPacketErrorRateHigh | |
| expr: avg by (instance) (irate(node_network_receive_errs_total{device=~“eth0|eth1|ens33|ens37”}[1m])) > 15 | |
| for: 3m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} 接收错误包 速率过高” | |
| description: “Network 接收错误包 速率超过 15个/秒” | |
| value: “{{ $value }}” | |
| – alert: NodeNetworkNetoutPacketErrorRateHigh | |
| expr: avg by (instance) (irate(node_network_transmit_packets_total{device=~“eth0|eth1|ens33|ens37”}[1m])) > 15 | |
| for: 3m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} 发送错误包 速率过高” | |
| description: “Network 发送错误包 速率超过 15个/秒” | |
| value: “{{ $value }}” | |
| – alert: NodeProcessBlockedHigh | |
| expr: node_procs_blocked{job=“node-service”} > 10 | |
| for: 10m | |
| labels: | |
| severity: warning | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} 当前被阻塞的任务的数量过多” | |
| description: “Process 当前被阻塞的任务的数量超过 10个” | |
| value: “{{ $value }}” | |
| – alert: NodeTimeOffsetHigh | |
| expr: abs(node_timex_offset_seconds{job=“node-service”}) > 3 * 60 | |
| for: 2m | |
| labels: | |
| severity: info | |
| instance: “{{ $labels.instance }}” | |
| annotations: | |
| summary: “instance: {{ $labels.instance }} 时间偏差过大” | |
| description: “Time 节点的时间偏差超过 3m” | |
| value: “{{ $value }}” |
重启prometheus容器:
| docker restart prometheus |
验证是否收到告警邮件,我们将node_exporter关闭,在被监控的ECS服务器操作:
| systemctl stop node_exporter |
然后刷新prometheus的页面,查看Alerts菜单,我们发现NodeDown规则处于PENDING状态:

等待一分钟后再次刷新查看,已经变成了FIRING状态:

这时候我们去查看下邮箱:

说明已经收到了告警邮件。现在我们把它恢复:
| systemctl start node_exporter |
然后我们就收到了服务恢复的告警邮件:

7 多容器启动管理
多容器配置,需要修改端口、数据存储路径等信息,例如:
Prometheus
| docker run -d –user root -p 9091:9090 –name prometheus-poc \ | |
| -v /home/mon/prometheus-poc/etc/prometheus.yml:/etc/prometheus/prometheus.yml \ | |
| -v /home/mon/prometheus-poc/rules:/etc/prometheus/rules \ | |
| -v /home/mon/prometheus-poc/data:/data/prometheus \ | |
| prom/prometheus \ | |
| –config.file=“/etc/prometheus/prometheus.yml” \ | |
| –storage.tsdb.path=“/data/prometheus” \ | |
| –web.listen-address=“0.0.0.0:9090” |
不同之处:
- -p 9091:9090
- –name prometheus-poc
- -v /home/mon/prometheus-poc/etc/prometheus.yml:/etc/prometheus/prometheus.yml
- -v /home/mon/prometheus-poc/rules:/etc/prometheus/rules
- -v /home/mon/prometheus-poc/data:/data/prometheus
Grafana
| docker run -d -p 3001:3000 -v /home/mon/grafana-poc:/var/lib/grafana –name=grafana-poc grafana/grafana:latest |
不同之处:
- -p 3001:3000
- –name=grafana-poc
- -v /home/mon/grafana-poc:/var/lib/grafana
Alertmanager
| docker run -d –user root -p 9094:9093 –name alertmanager-poc \ | |
| -v /home/mon/alertmanager-poc/etc/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ | |
| -v /home/mon/alertmanager-poc/data:/alertmanager/data | |
| prom/alertmanager:latest \ | |
| –config.file=“/etc/alertmanager/alertmanager.yml” \ | |
| –web.listen-address=“0.0.0.0:9093” |
不同之处:
- -p 9094:9093
- –name alertmanager-poc
- -v /home/mon/alertmanager-poc/etc/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- -v /home/mon/alertmanager-poc/data:/alertmanager/data